Abstract
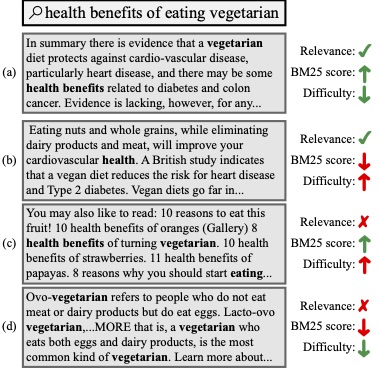
In precision-oriented tasks like answer ranking, it is more important to rank many relevant answers highly than to retrieve all relevant answers. It follows that a good ranking strategy would be to learn how to identify the easiest correct answers first (i.e., assign a high ranking score to answers that have characteristics that usually indicate relevance, and a low ranking score to those with characteristics that do not), before incorporating more complex logic to handle difficult cases (e.g., semantic matching or reasoning). In this work, we apply this idea to the training of neural answer rankers using curriculum learning. We propose several heuristics to estimate the difficulty of a given training sample. We show that the proposed heuristics can be used to build a training curriculum that down-weights difficult samples early in the training process. As the training process progresses, our approach gradually shifts to weighting all samples equally, regardless of difficulty. We present a comprehensive evaluation of our proposed idea on three answer ranking datasets. Results show that our approach leads to superior performance of two leading neural ranking architectures, namely BERT and ConvKNRM, using both pointwise and pairwise losses. When applied to a BERT-based ranker, our method yields up to a 4% improvement in MRR and a 9% improvement in P@1 (compared to the model trained without a curriculum). This results in models that can achieve comparable performance to more expensive state-of-the-art techniques.