Efficient Document Re-Ranking for Transformers by Precomputing Term Representations
Abstract
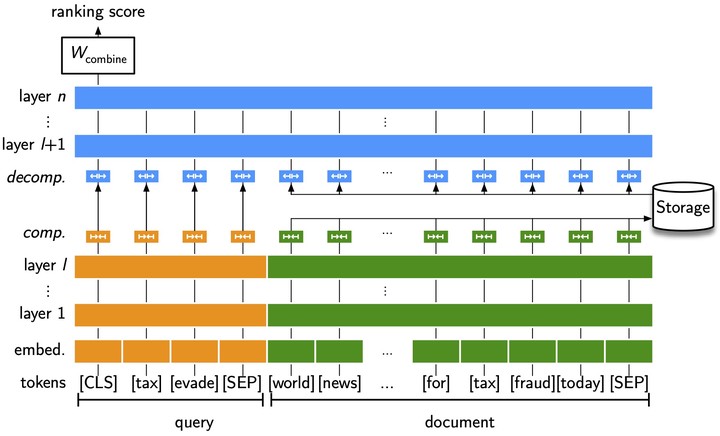
Deep pretrained transformer networks are effective at various ranking tasks, such as question answering and ad-hoc document ranking. However, their computational expenses deem them cost-prohibitive in practice. Our proposed approach, called PreTTR (Precomputing Transformer Term Representations), considerably reduces the query-time latency of deep transformer networks (up to a 42x speedup on web document ranking) making these networks more practical to use in a real-time ranking scenario. Specifically, we precompute part of the document term representations at indexing time (without a query), and merge them with the query representation at query time to compute the final ranking score. Due to the large size of the token representations, we also propose an effective approach to reduce the storage requirement by training a compression layer to match attention scores. Our compression technique reduces the storage required up to 95% and it can be applied without a substantial degradation in ranking performance.